
This is a pretty exciting moment, the first public alpha release of a brand new project: Hibernate OGM. Hibernate OGM stands for Object Grid Mapping and its goal is to offer a full-fledged JPA engine storing data into NoSQL stores. This is a rather long blog entry so I've split it into distinct sections from goals to technical detail to future.
Note that I say it's the first public alpha because the JBoss World Keynote 2011 was powered by Hibernate OGM Alpha 1. Yes it was 100% live and nothing was faked, No it did not crash :) Sanne explained in more detail how we used Hibernate OGM in the demo. This blog entry is about Hibernate OGM itself and how it works.
Why Hibernate OGM
One of the objectives of the Infinispan team is to offer a higher level API for object manipulation. One thing leading to another, we have experimented with JPA and Hibernate Core's engine to see if this could fit the bill: looks like it does. The vision has quickly expanded though and Hibernate OGM is now an independent project aiming to offer JPA on top of other NoSQL stores too.
At JBoss, we strongly believe that provided tools become available, developers, applications and whole corporations will exploit new data usage patterns and create value out of it. We want to speed up this adoption / experimentation and bring it to the masses. NoSQL is like sex for teenagers: everybody is talking about it but few have actually gone for it. It's not really surprising, NoSQL solutions are inherently complex, extremely diverse and come with quite different strengths and weaknesses: going for it implies a huge investment (in time if not money). (One of) JBoss's goal is to help lower the barrier of entry and Hibernate OGM is right inline with this idea.
We want to simplify the programmatic model of various NoSQL approaches by offering a familiar one to many Java developers: JPA. The good thing about a familiar and common programmatic model is that it's easy to try out one data backend and move to another down the road without affecting dramatically the application design.
So when should you use Hibernate OGM? We are not claiming (that would be foolish) that all NoSQL use cases can and will be addressed by JPA and Hibernate OGM. However, if you build a domain model centric application, this will be a useful tool for you. We will also expand Hibernate OGM feature set and use cases to address different areas (like fronting a RDBMS with a NoSQL store). Besides, Hibernate OGM is not an all or nothing tool. You can very well use it for some of the datastore interactions and fall back to your datastore native API for more advanced features or custom query mechanism. No lock-in here.
How does it work
Basically, we are reusing the very mature Hibernate Core engine and trick it into storing data into a grid :) We plug into Hibernate Core via two main contracts named Loader and Persister. As you could expect, these load and persist/update/delete entities and collections.
Early in the project, we have decided to keep as much of the goodies of the relational model as possible:
- store entities as tuples
- keep the notion of primary key and foreign key (foreign keys violation are not enforced though - yet)
- keep an (optional) indirection layer between the application data model and the datastore data model
- limit ourselves to core data types to maximize portability
Entities are stored as tuples which essentially is a Map<String,Object> where the key is the column name and the value is the column value. In most cases, the property is mapped to a column but this can be de-correlated (@Column). An entity tuple is accessible via a single key lookup. Associations as a bit trickier because unlike RDBMs, many NoSQL stores and Grid specifically do not have build-in query engines and thus cannot query for associated data easily. Hibernate OGM stores navigational information to go from a given entity to its association information. This is achieved by a single key lookup. The drawback here is that writing requires several key lookup / update operations.
Here is a schema representing the object model, the relational model and finally how data is stored in the data grid.
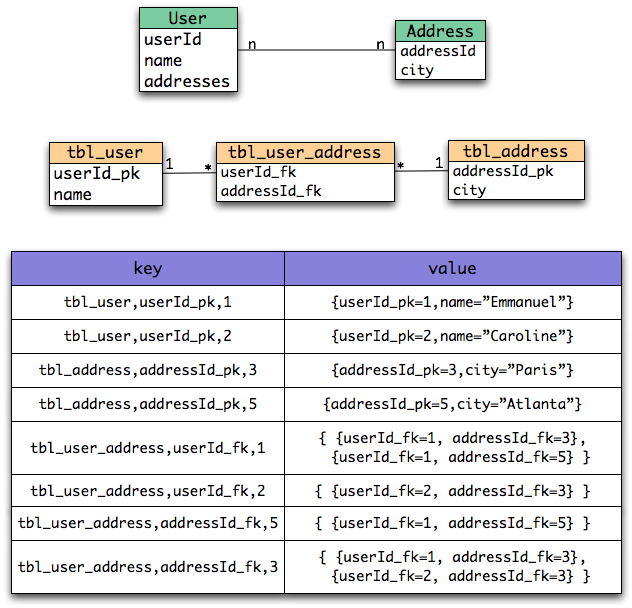
All this means that we do not store entity objects in the grid but rather a dehydrated version of them. And this is a good thing. Blindly serializing entities would have led to many issues including:
- When entities are pointing to other entities, are you storing the whole graph?
- How do you guarantee object identity or even consistency amongst duplicated objects?
- What happens in case of class schema change?
- How do you query your data?
- How to replicate class definitions to other nodes?
Unless you store relatively simple and short lived data, never go for blind serialization. Hibernate OGM does this smart dehydration for you.
For more information on how we did things, please have a look at the architecture section of Hibernate OGM's reference documentation.
What is supported today and what about tomorrow?
Today Hibernate OGM is quite stable for everything CRUD (Create, Read, Update, Delete) and of course extremely stable for all the JPA object lifecycle rules as we simply reuse Hibernate Core's engine. Here is an excerpt on the things supported but for the full detail, please go check the reference documentation that list what is not supported.
- CRUD operations for entities
- properties with simple (JDK) types
- embeddable objects
- entity hierarchy
- identifier generators (TABLE and all in-memory based generators today)
- optimistic locking
- @ManyToOne, @OneToOne, @OneToMany and @ManyToMany associations
- bi-directional associations
- Set, List and Map support for collections
- most Hibernate native APIs (like Session) and JPA APIs (like EntityManager)
- same bootstrap model found in JPA or Hibernate Core: in JPA, set <provider> to org.hibernate.ogm.jpa.HibernateOgmPersistence and you're good to go
Since Hibernate OGM is a JPA implementation, you simply configure and use it like you would use Hibernate Core and you map your entities with the JPA annotations. Same thing, nothing new here. Check our the getting started section in our reference documentation.
What we do not support today is JP-QL. Support for simple-ish queries is due very soon and will be based on Hibernate Search indexing and querying capabilities. However, you can already use Hibernate Search directly with Hibernate OGM. You can even store your index in Infinispan, in Voldemort or in Cassandra (and others).
Also, the NoSQL solution initially supported is Infinispan. The reasons behind it are quite simple:
- we had to start with one
- key/value is a simple model
- we can kick some JBoss employees in the nuts if we find a bug or need a feature
- we have a very good in-house knowledge about Infinispan's isolation and transaction model and it happens to be quite close to the relational model
That being said, we do intend to support other NoSQL engines especially other key/value engines very soon. We have some abstractions in place already so they do need polishing. If you know a NoSQL solution and want to write a dialect for Hibernate OGM, please come talk to us and contribute.
Future
We are at the very beginning of the project and the future is literally being shaped. Here are a few thing we have in plan:
- support for other key/value pair systems
- support for other NoSQL engine
- declarative denormalization: we have focused on feature so far, performance check and association denormalization is planned)
- support for complex JP-QL queries including to-many joins and aggregation
- fronting existing JPA applications
This is a community driven effort, if one of these areas interest you or if you have other ideas, let us know!
How to download and come contribute!
You can download the jars on JBoss.org's Maven repository or of course download the distribution (I'd recommend you download the distribution as it contains a consistent documentation with the release you wish to use).
Speaking of documentation, we tried to initially release with a fairly advanced reference documentation. In particular, the getting started and the architecture sections are quite complete: check it out.
Last but not least, Hibernate OGM is in its infancy, if you're interested in contributing or have ideas on how things should be done, let us know and speak up!
Many thanks to the team, to external contributors as well as the Cloud-TM project members for their support and tests.
Emmanuel and the team.
