
Introduction
When it comes to optimizing queries, you should listen to Markus Winand. While reading this great article about Nested Loops, I stumbled on the following remark:
The query has the expected left join but also an unnecessary distinct keyword. Unfortunately, JPA does not provide separate API calls to filter duplicated parent entries without de-duplicating the child records as well. The distinct keyword in the SQL query is alarming because most databases will actually filter duplicate records. Only a few databases recognize that the primary keys guarantees uniqueness in that case anyway.
Nested Loops
Markus is right. Not only that the DISTINCT keyword is redundant, but it’s affecting performance as well.
Because we want Hibernate to be a solution for high-performance data access systems, I created the HHH-10965 Jira issue which is fixed in Hibernate 5.2.2.
This article is going to demonstrate the redundant DISTINCT problem, and how you can overcome it in Hibernate 5.2.2.
Domain Model
For test sake, let’s assume that we want to develop a book store application.
The two most important entities within our system are the Book and the Person who’s written the book.
To simplify our design, we’ll assume that every Book is written by a single author, although in reality, this might not always be the case.
Therefore, the Domain Model looks like this:
@Entity(name = "Person") @Table( name = "person")
public class Person {
@Id @GeneratedValue
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@OneToMany(mappedBy = "author", cascade = CascadeType.ALL)
private List<Book> books = new ArrayList<>( );
public Person() {}
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void addBook(Book book) {
books.add( book );
book.setAuthor( this );
}
//Getters and setters omitted for brevity
}
@Entity(name = "Book") @Table( name = "book")
public class Book {
@Id @GeneratedValue
private Long id;
private String title;
@ManyToOne
private Person author;
public Book() {}
public Book(String title) {
this.title = title;
}
//Getters and setters omitted for brevity
}Every Book has an author property indicating the Person who wrote it.
Using DISTINCT
Supposing we need to select a particular author, we might want to provide a list of last names so that the user can trim down the author list. This can be done easily with the following query:
List<String> lastNames = entityManager.createQuery(
"select distinct p.lastName " +
"from Person p", String.class)
.getResultList();
assertTrue(
lastNames.size() == 2 &&
lastNames.contains( "King" ) &&
lastNames.contains( "Mihalcea" )
);As expected, Hibernate generates the following SQL query:
SELECT DISTINCT
p.last_name as col_0_0_
FROM person pIn this context, the use of DISTINCT is understandable since we want duplicates to be removed.
So far, so good, But, let’s now assume we want to fetch all Person entities along with their Book(s):
List<Person> authors = entityManager.createQuery(
"select p " +
"from Person p " +
"left join fetch p.books", Person.class)
.getResultList();
authors.forEach( author -> {
log.infof( "Author %s wrote %d books",
author.getFirstName() + " " + author.getLastName(),
author.getBooks().size()
);
} );When executing the query above, Hibernate generates the following output:
SELECT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
-- Author Gavin King wrote 2 books
-- Author Gavin King wrote 2 books
-- Author Stephen King wrote 1 books
-- Author Vlad Mihalcea wrote 1 booksAs we can see we have a duplicated entry for Gavin King.
This is because we have 4 records in our ResultSet, the count being given by the number of books associated with the currently selected authors.
To remove duplicated entries, JPA offers the DISTINCT keyword:
List<Person> authors = entityManager.createQuery(
"select distinct p " +
"from Person p " +
"left join fetch p.books", Person.class)
.getResultList();
authors.forEach( author -> {
log.infof( "Author %s wrote %d books",
author.getFirstName() + " " + author.getLastName(),
author.getBooks().size()
);
} );This time, Hibernate generates the following output:
SELECT DISTINCT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
-- Author Gavin King wrote 2 books
-- Author Stephen King wrote 1 books
-- Author Vlad Mihalcea wrote 1 booksThere are no duplicates any more. Duplicates are removed by Hibernate when building the graph of entities, after the ResultSet is fetched from JDBC.
Spotting the problem
However, have you spot the DISTINCT keyword in the SQL query?
In this particular case, DISTINCT does not bring any value since we don’t have duplicated entries in the JDBC ResultSet.
Not only this is redundant, but DISTINCT can cause performance problems because the result set must be sorted by the query executor.
For instance, running the previous query on PostgreSQL generates the following execution plan:
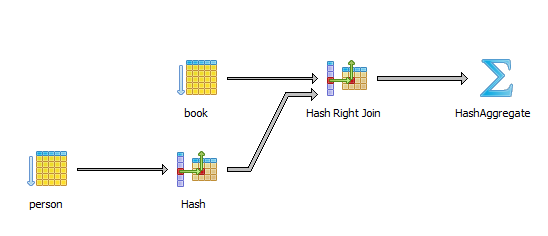
The HashAggregate stage is associated with sorting the result set and ensuring there is no duplicate entry.
There’s a very good explanation of HashAggregate inner working on depesz.com.
Basically, the result set is sorted so that duplicated rows come one after other, therefore a row is discarded if it’s identical to the previous record.
When running the EXPLAIN FORMAT=JSON against the same query using DISTINCT on MySQL, we get the following execution plan:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "5.02"
},
"duplicates_removal": {
"using_temporary_table": true,
"using_filesort": false,
"nested_loop": [
{
"table": {
"table_name": "p",
"access_type": "ALL",
"rows_examined_per_scan": 3,
"rows_produced_per_join": 3,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.60",
"prefix_cost": "1.60",
"data_read_per_join": "4K"
},
"used_columns": [
"id",
"first_name",
"last_name"
]
}
},
{
"table": {
"table_name": "b",
"access_type": "ALL",
"possible_keys": [
"FKi7lkcmacourlqkkn4uo1s4svl"
],
"rows_examined_per_scan": 4,
"rows_produced_per_join": 12,
"filtered": "100.00",
"using_join_buffer": "Block Nested Loop",
"cost_info": {
"read_cost": "1.02",
"eval_cost": "2.40",
"prefix_cost": "5.02",
"data_read_per_join": "9K"
},
"used_columns": [
"id",
"title",
"author_id"
],
}
}
]
}
}
}|
When using MySQL 5.6.5 or later, you have the option of using the JSON EXPLAIN format, which provides lots of information compared to the TRADITIONAL EXPLAIN output. |
You can easily spot the duplicates_removal and using_temporary_table attributes that are associated with the sorting phase incurred by the DISTINCT keyword.
MySQL creates a temporary table to store the intermediate result set and apply a sorting algorithm to discover duplicates.
MySQL offers a DISTINCT/GROUP BY optimization technique to avoid the temporary table creation,
but that requires an index that features the same columns in the same exact order with the SELECT query. In our case, this is not very feasible.
|
The |
Fixing the problem
That was the main reason for the HHH-10965 issue that was recently fixed, and which adds the following JPA-level Query Hint:
List<Person> authors = entityManager.createQuery(
"select distinct p " +
"from Person p " +
"left join fetch p.books", Person.class)
.setHint( QueryHints.HINT_PASS_DISTINCT_THROUGH, false )
.getResultList();The hibernate.query.passDistinctThrough hint tells Hibernate to avoid passing the DISTINCT keyword to the actual SQL query.
Therefore, we get the following output:
SELECT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
-- Author Gavin King wrote 2 books
-- Author Stephen King wrote 1 books
-- Author Vlad Mihalcea wrote 1 booksThis way, the Person are de-duplicated by Hibernate while the SQL query features no useless DISTINCT keyword.
Now, the query plan for PostgreSQL becomes:
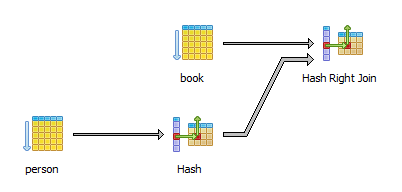
There’s no longer a HashAggregate stage, meaning that the database is not doing any redundant result set sorting.
The query plan for MySQL looks like this:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "5.02"
},
"nested_loop": [
{
"table": {
"table_name": "p",
"access_type": "ALL",
"rows_examined_per_scan": 3,
"rows_produced_per_join": 3,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.60",
"prefix_cost": "1.60",
"data_read_per_join": "4K"
},
"used_columns": [
"id",
"first_name",
"last_name"
]
}
},
{
"table": {
"table_name": "b",
"access_type": "ALL",
"possible_keys": [
"FKi7lkcmacourlqkkn4uo1s4svl"
],
"rows_examined_per_scan": 4,
"rows_produced_per_join": 12,
"filtered": "100.00",
"using_join_buffer": "Block Nested Loop",
"cost_info": {
"read_cost": "1.02",
"eval_cost": "2.40",
"prefix_cost": "5.02",
"data_read_per_join": "9K"
},
"used_columns": [
"id",
"title",
"author_id"
],
"attached_condition": "<if>(is_not_null_compl(b), (`hibernate_orm_test`.`b`.`author_id` = `hibernate_orm_test`.`p`.`id`), true)"
}
}
]
}
}This fix is going to be available in Hibernate 5.2.2, so one more reason to upgrade!
If you enjoyed this article, you might be interested in reading my book as well.
