
Overview
I believe that this probably one of the most expected articles to come. It will touch the RichFaces iteration component in-depth, covering advanced models which we are using under the hood. Actually real enterprise application using huge data sets, applies paging with lazy data loading, uses sorting, filtering, selection and the other features which makes then application really rich and interactive. So in most cases you could not rely on simple lists or maps with data wrapped using default models. And in order to achieve the best RichFaces tables experience with a good performance and scalability you need to understand the base principles of our models.
Models sample
At first I would like to introduce new sample available on our live demo – Arrangeable Model Sample. It works using Hibernate Entity Manager and all the paging/sorting/filtering operations really performed at DB level instead of performing in wrapped model.
In that article I will guide you through the base points which you should look in that sample in order to get main ideas and be able to work on your own models.
Why do we need the models
Let's start from a good question – why RichFaces introduces custom models having JSF javax.faces.model.DataModel contract already. And the reason is pretty simple. In difference with JSF 2 implementation which is supposed just to provide basic stuff RichFaces introduces new rich components and adds new features on top of them. Here is just overview:
- Trees components family. With support of swing-based data models and RichFaces custom data models. With additional providers which allows to create data model declaratively from any custom non-hierarchical model. With selection feature plugged and available using different modes (Ajax, client, server)
- Tables components family. RichFaces unifies sorting/filtering/paging features among two rich tables. It adds the ability of master-detail layouts creation in rich:dataTable with the built-in feature of collapse/expand details subtables. It adds Ajax lazy loading of the data on vertical scroll and selection with rich:extendedDataTable. And so on..
Of course all that stuff requires good model base. And in order to standardize the API between different components providing unified contract to the RichFaces developers we designed our models.
ExtendedDataModel Overview
From the beginning let me introduce our models principles and then later we will see how them are implemented in the showcase demo.
ExtendedDataModelis a base model abstract class which provides the contract for all the other models particular implementations. Let’s see closer to that class:
public abstract class ExtendedDataModel<E> extends DataModel<E> {
public abstract void setRowKey(Object key);
public abstract Object getRowKey();
public abstract void walk(FacesContext context, DataVisitor visitor, Range range, Object argument);
}
Well, we seeing new entity introduced there. And it’s rowKey. Let’s see the goal of that entity. Working with complex data structures (like trees) and using advanced UI component features like filtering/sorting/paging/selection in tables we need to have a simple way to identify the object in the model. And just rowIndex’es doesn’t play nice enough as requires additional complex look-up mechanisms (to identify db object according to index in wrapped model) to do that. And with the rowKey you could just use the same id which you are using at db level.
Besides you see walk() method introduced there. RichFaces iteration components uses visitor pattern while working with model. So that method should perform model iteration and call the visitor passed as a parameter in order to handle every object in the model.
ExtendedDataModel implementations
- SequenceDataModel – default implementation of the ExtendedDataModel for the tables. Used when filtering and sorting not used by the component.
- ArrangeableModel – implementation of the ExtendedDataModel which implements Arrangeable interface additionally which are used to add sorting and filtering support.
- TreeSequenceKeyModel abstract model and all the models which extends it used by the tree component family. That model is out of scope for that article.
Sample Code
At first I would like to say that will not describe all the code used in the sample. You could easily check it at showcase live or obtain from SVN repository and explore in your favorite IDE. Besides the fact that it will be boring and will make article really huge I also want to say that the goal of that write-up – to guide you in the right direction while reviewing RichFaces data models usage principles.
And overview of that sample functionality:
- Obtaining the list of Person object s from the db according to given filtering and sorting rules
- Displaying objects using the rich:dataTable
- Addition of the controls which control sorting and filtering
- Addition of the rich:dataScroller which allows breaking the data loading from db to the pages.
Sample Code – Base Person entity
That would be self-explanatory I believe. We just using simple and frequently used classes to define Person object.
@Entity
public class Person {
private String name;
private String surname;
private String email;
@Id
@GeneratedValue
private Long id;
//getters and setters
}
Sample Code – Generic Model
Now let’s look closer to the model code.
JPADataModel–is a generic model which supposed to provide unified approach of working with data for all implementers. It’s parameterized with the class which should be defined to work with particular entity classes in models which will implement it. And besides it passed with the EntityManager in order the implementer classes to be responsible for particular EntityManager lookup.
Also from the beginning you should note abstract getId(T t) method which should be also implemented in the model which implements that abstract model. It should return the id of the particular entity which will be used as rowKey in that model.
Now let’s review two most important methods there. And let’s look to arrange() method from the beginning. It probably too simple to have it listed but any way:
public void arrange(FacesContext context, ArrangeableState state) {
arrangeableState = state;
}
Just wanted to give some simple explanation of why we perform just simple storing of the passed state in the model property without any further processing. If you will look or already looked to RichFaces sources you will see that default ArrangeableModel implementation of that method performs actual sorting and filtering. But that’s done because our default model works with wrapped model (e.g. simple list or map passed as rich:dataTable value). But in our case we will load the data from db according to current data table page and apply sorting and filtering using db queries also. So we just need to store all the information passed from component in ArrangeableState object for future usage in walk().
Now let’s look to walk() method:
@Override
public void walk(FacesContext context, DataVisitor visitor, Range range, Object argument) {
CriteriaQuery<T> criteriaQuery = createSelectCriteriaQuery();
TypedQuery<T> query = entityManager.createQuery(criteriaQuery);
SequenceRange sequenceRange = (SequenceRange) range;
if (sequenceRange.getFirstRow() >= 0 && sequenceRange.getRows() > 0)
{
query.setFirstResult(sequenceRange.getFirstRow());
query.setMaxResults(sequenceRange.getRows());
}
List<T> data = query.getResultList();
for (T t : data) {
visitor.process(context, getId(t), argument);
}
}
The component calls that method a few times during lifecycle and expects it to iterate over the model calling the DataVisitor which will process every object (e.g. encode row for the object at render phase).
Besides visitor, table component passes the Range object there which contains information about from which row the table wants get the data (defined using first attribute or set by rich:dataScroller while switching pages) and the number of rows to fetch (defined using rows attribute). So all we are doing here – just creating query with given sort, filtering and range parameters, loading data from db to the List of entities and finally iterate over that list passing every object to DataVisitor for processing.. You probably will be interested in createSelectCriteriaQuery() method as it performs actual applying of sort and filter parameters. But actually I would like to leave it just to you because JPA queries creation question really out of scope of that article and well explained already at more specific resources.
Besides you may be interested to look into getRowCount() method:
@Override
public int getRowCount() {
CriteriaQuery<Long> criteriaQuery = createCountCriteriaQuery();
return entityManager.createQuery(
criteriaQuery).getSingleResult().intValue();
}
So there we’re applying sorting and filtering creating the criteria in order to return the rowCount for current component state.
Sample Code – Specific Model Class
The implementation of our generic model placed in PersonBean and defined with the next code:
@ManagedBean
@SessionScoped
public class PersonBean implements Serializable {
//...
private static final class PersonDataModel extends JPADataModel<Person> {
private PersonDataModel(EntityManager entityManager) {
super(entityManager, Person.class);
}
@Override
protected Object getId(Person t) {
return t.getId();
}
}
//...
private EntityManager lookupEntityManager() {
FacesContext facesContext = FacesContext.getCurrentInstance();
PersistenceService persistenceService =
facesContext.getApplication().
evaluateExpressionGet(facesContext, "#{persistenceService}",
PersistenceService.class);
return persistenceService.getEntityManager();
}
public Object getDataModel() {
return new PersonDataModel(lookupEntityManager());
}
//...
}
So actually all we are doing there - performing lookup of entity manager and initiating the particular model implementation with the Person class as entity class and that entity manager.
Sample Code – Page Code
We used two pages there. At first arrangeableModel-sample.xhtml:
<h:form id="form">
<rich:dataTable keepSaved="true" id="richTable" var="record"
value="#{personBean.dataModel}" rows="20">
<ui:include src="jpaColumn.xhtml">
<ui:param name="bean" value="#{personBean}" />
<ui:param name="property" value="name" />
</ui:include>
<ui:include src="jpaColumn.xhtml">
<ui:param name="bean" value="#{personBean}" />
<ui:param name="property" value="surname" />
</ui:include>
<ui:include src="jpaColumn.xhtml">
<ui:param name="bean" value="#{personBean}" />
<ui:param name="property" value="email" />
</ui:include>
<f:facet name="footer">
<rich:dataScroller id="scroller" />
</f:facet>
</rich:dataTable>
</h:form>
Nothing pretty interesting there. We just defining table pointed to our model and including the columns passing properties of the person and the bean to it.
And the second is jpaColumn.xhtml:
<ui:composition>
<rich:column sortBy="#{property}"
sortOrder="#{bean.sortOrders[property]}" filterValue="#{bean.filterValues[property]}"
filterExpression="#{property}">
<f:facet name="header">
<h:commandLink action="#{bean.toggleSort}">
#{bean.sortOrders[property]}
<a4j:ajax render="richTable" />
<f:setPropertyActionListener target="#{bean.sortProperty}"
value="#{property}" />
</h:commandLink>
<br />
<h:inputText value="#{bean.filterValues[property]}">
<a4j:ajax render="richTable@body scroller" event="keyup" />
</h:inputText>
</f:facet>
<h:outputText value="#{record[property]}" />
</rich:column>
</ui:composition>
That’s actually more interesting for us. Most important what you should note there that we passing just Person properties names as sortBy and filterExpression values. Usually you used EL binding to iteration object property and boolean expression in case you using our default models. But that’s not the case for us. As we implementing our model with in-db sorting and filtering – all we need to know just properties names and we will apply the rules in queries like you could see in the model.
Exercises
That sample is still not ideal for sure. Most important you could easily see that there is absolutely no caching. Every time when walk() or getRowCount() called it queries the db with the request for data. You should add it on your own because there is actually no unified recipe for all the situations. Somebody could need just to read the data from db once when filtering sorting or page changes and be sure that it never changes more between requests. In some cases you should consider that data could be inserted/deleted/edited concurrently by different users so the List obtained in walk() method could be changed even between different walk calls and so on. So it’s up to you to define the rules for that. The same applied to rowCount. It’s highly important to cache it also as possible because it’s called also multiple time during request (by both table and data scroller)
Besides you might want to add Weld/Seam in order to be able to tie beans, entities and services in more graceful way.
The result
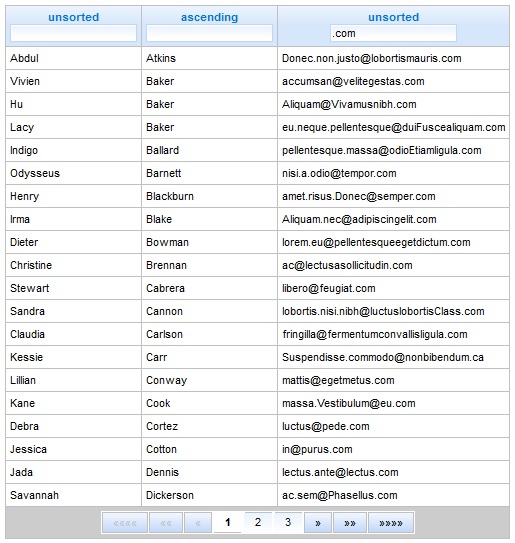
Even considering all you could open the demo that blog article would be boring without at least single screenshot of the result we achieved. So here is the table after we performed sorting by surname and filtered by emails to obtain only persons with emails in .com
domain:
More information
As usually please refer to RichFaces Documentation to get more info from JavaDoc's and references.
