
Hi,
I just thought that the release of Hibernate Search 3.1.0.Beta2 would be a good time to announce another clustering possibility for Hibernate Search - Terracotta clustering. Why would one use Terracotta? Well, there are several potential benefits of Terracotta clustering over the default JMS clustering currently used by Hibernate Search?
- Updates to the index are immediately visible to all nodes in the cluster
- You don't have the requirement of a shared file system
- The faster RAMDirectory is used instead of the slower FSDirectory
But let's get started. You can download the code for the following example here or you can just download the binary package. At the moment the code is not yet part of the Search codebase, but probably it will at some stage.
First you will need to download and install Terracotta. I am using the 2.6.2 release. Just unpack the release into a arbitrary directory. I am using /opt/java/terracotta. Next you will the main Compass jar. You can use this jar. Place this jar into the modules directory of your terracotta installation. This solution does not rely on any Compass classes per se, but utilizes a custom RAMDirectoy implementation - org.compass.needle.terracotta.TerracottaDirectory. This is required since Lucene's RAMDirectory is not Terracotta clusterable out of the box. Let's start the terracotta server now. Switch into the bin directory of your terracotta installation and run ./start-tc-server.sh. Check the log to see whether the server started properly.
Next download and extract hsearch-demo-1.0.0-SNAPSHOT-dist.tar.gz. The dist package currently assumes that you have a mysql database running with a database hibernate and a username/password of hibernate/hibernate. You can change these settings and use a different database if you build the dist package from the source, but more to this later. The dist further assumes that you have installed Terracotta under /opt/java/terracotta. If this is not the case you can change the repository node in config/tc-config.xml. Provided that you have a running mysql database and tc-config.xml properly reflects your terracotta installation directory things should be as easy as just typing ./run.sh. The scripts will ask you whether you want to start a standalone application or a terracotta clustered one. Just press 't' to start a terracotta clustered app. You should get up a Swing JTable:
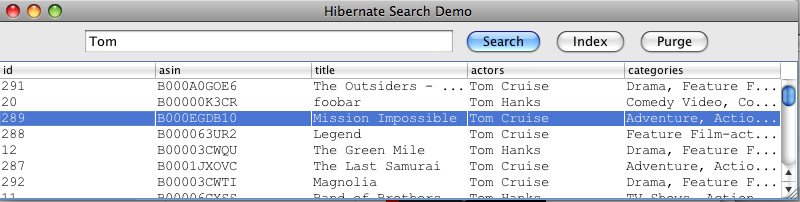
Press the index button to create an initial index. The data model is based on the former Seam sample DVD store application. Once the index is created just search for example for Tom. You should get a list of DVDs in the table. Experiment a little with the application and different queries. When you are ready start a second instance of the application by running ./run.sh again. You won't have to create the index again. In the second instance the DVDs should be searchable right away. You can also edit the title field of a DVD in one application and search for the updated title in the other. Also try closing both applications and restarting a new instance. Again DVDs should be searchable right away. The Terracotta server keeps a persistent copy of the clustered Lucene directory.
Ok, now it is time to build the application from the source. This will allow you to actually inspect the code and change things like database settings. Donwload hsearch-demo-1.0.0-SNAPSHOT-project.tar.gz and unpack the tarball. Import the maven project in your preferred IDE. To build the project you will need to define the following repositories in your settings.xml:
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/maven2</url>
</repository>
<repository>
<id>compass-project.org</id>
<url>http://repo.compass-project.org</url>
</repository>
If you want to use a different database you can add/modify the profiles section in pom.xml. Also have a look at src/main/scripts/tc-config.xml and adjust any settings which differ in your setup. Once you are happy with everything just run mvn assembly:assembly to build your own version of the application.
I basically just started experimenting with this form of clustering and there are still several open questions:
- How does it perform compared to the JMS clustering?
- What are the limits for the RAMDirectory size?
- How can I add failover capabilities?
I am planning to do some more extensive performance tests shortly. Stay tuned in case you are interested.
--Hardy
P.S. It would be great if someone actually tries this out and let me know if it works. As said, it's still work in progress. Any feedback is welcome :)
