
This blog entry is a general overview of the Bean Validation specification. Future blog entries will follow and will dive into specific aspects of the specification.
We have just released an early draft review of JSR 303 Bean Validation. The goal of this draft is to gather feedbacks and comments from the multi-facets community
- application developers (SE, EE, GUI, process, database)
- library developers
- tool developers
- other JSR expert groups including JSF 2.0, Java Persistence 2.0 and WebBeans
Please download the specification draft and give us feedback.
Goals
Validating data is a common task that is spread across several (if not all) layers of today's applications. Because each layer defines validation rules its own way, duplication and errors are quite common.
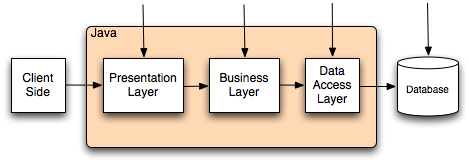
The Bean Validation specification addresses this problem by providing:
- an extensible annotation-based validation declaration model (XML deployment descriptors will be available as well)
- a standard runtime validation API
- a standard metadata query API
By providing a standard frame set around object validation, the specification aims at being the main provider for validation declaration and validation execution in the Java ecosystem. The same set of validations will be shared by all the application layers.
Expressing constraints
Constraints are primarily expressed through annotations. Adding a constraint on a class, field or getter is as simple as adding a constraint annotation on it. The annotated element value is checked by the constraint.
public class Address {
@NotEmpty @Max(50)
private String street1;
@Max(50)
private String street2;
@Max(9) @NotNull
private String zipcode;
...
}
Validating an object is equivalent to validate all the constraints declared on:
- its fields
- its getters
- its class
- its superclasses
- its interfaces
Mind your own constraint
Constraints are not limited to built-in annotations. Any application can define its own additional set of constraints. A constraint is comprised of:
- an annotation
- a constraint validation implementation
While the annotation expresses the constraint on the domain model, the validation implementation decides whether a given value passes the constraint or not.
message
A constraint can define a custom error message returned when failure occurs.
public class Address {
@NotEmpty(message="The street is mandatory")
private String street1;
The specification provides a way to externalize these messages: this will be covered in a later post.
object graph validation
It is handy to validate an object graph as a whole rather than validate every single object manually. @Valid allows you to include associated objects to the validation process
public class Order {
@OrderNumber private String orderNumber;
@Valid @NotNull private Address delivery;
}
When an order object is validated, its address is validated as well.
Validating constraints
A Validator validates objects (graphs) of a given type. When an object is validated, all declared constraints are validated (from fields, getters, the class itself and associated objects if marked as such). The validation will process all constraints and return the list of all failing ones. This is quite useful to display all erroneous fields in a user interface.
Validator<Address> addressValidator = ...;
for (InvalidConstraint<Address> error : addressValidator.validate(address) ) {
displayErrorByField(error.getPropertyPath(), error.getMessage());
}
The API also allows to validate a given property rather than the whole object graph for finer grained validation, possibly even before setting the value. This situation arises when an object is gradually populated and needs to be validated.
//apply the street1 constraints on the value
addressValidator.validateValue("street1", "3340 peachtree Rd NE");
It is also possible to validate a subset of the declared constraints rather than all available constaints (using the notion of constraint groups). This is useful in two scenarios:
- validate a gradually populated object graph (wizard style UI or use case driven validation)
- validate a set of constraints before an other set of constraints (the second relying on the first or being expensive resource-wise)
Groups will be covered in a future post.
Sharing constraint metadata
The Bean Validation API exposes all the constraint metadata for a given class:
- describes the constraints of a given element
- exposes the constraint properties
- etc
Metadata information is useful for tools (such as IDEs) and libraries interacting beyond the frontier of Java (database, javascript libraries and so on).
The grand scheme of things
The goal of JSR 303 is to be the main runtime checking solution and metadata repository for validation rule. This common language between application developers, libraries and JSRs in need for validation (runtime and metadata) will free Java developers from multiple constraint declarations and incompatible validation implementations.
We have specifically planned to work with expert groups from JSF 2.0, Java Persistence 2.0 and WebBeans to offer a smooth and homogeneous integration at the Java platform level. You can envision your constraints propagated to the database schema, to AJAX UI components and checked at various levels of the Java application (presentation, business, persistence layers), all from the same declaration source: your domain model.
This blog entry only brushes the main usages and APIs of the Bean Validation specification. I will follow with some posts covering in more depth:
- how to write your own constraints and why it matters
- groups: define subsets of constraints, why and how
- beyond the Java land: the metadata API
Please download the specification draft and give us feedback.
